CLIP has become a cornerstone of modern AI, powering everything from zero-shot image classification to serving as the vision backbone for multimodal LLMs.
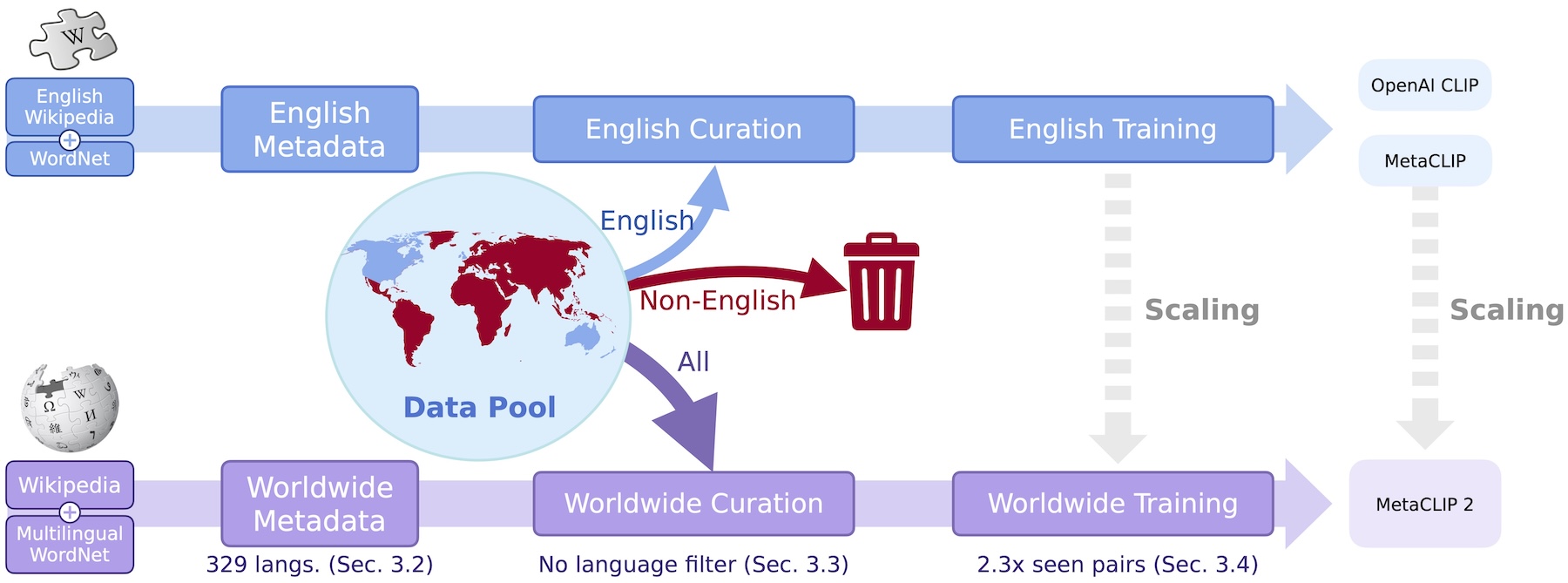
We've successfully trained CLIP on billions of English image-text pairs from the web. But here's the problem: what about the rest of the world that makes up the other 60% of the web?
When we try to scale CLIP to learn from worldwide web data, we hit two major roadblocks.
First, there's no existing methods to curate and balance data from non-English languages—the methods that work for English won't trivially transfer.
Second, existing multilingual CLIP models tend to perform worse than their English-only counterparts.
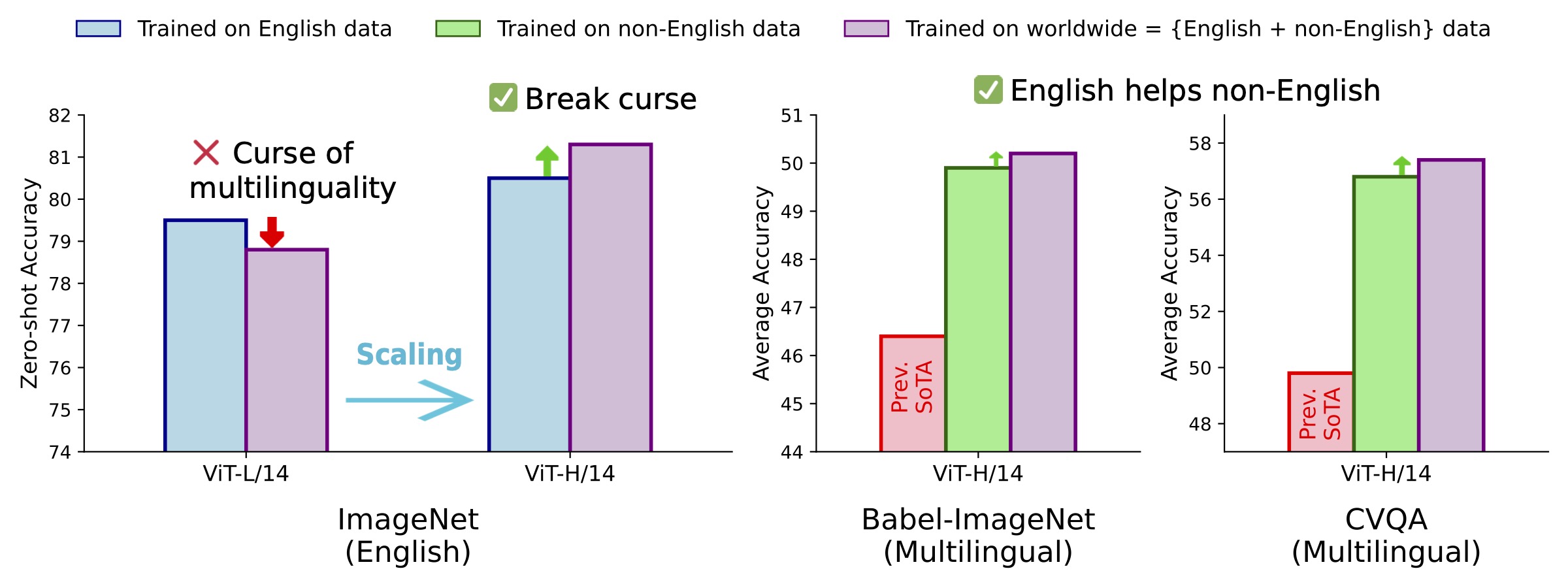
It's the classic "curse of multilinguality": trying to do everything means you end up doing nothing particularly well. It's common for a multilingual model to perform worse than an English-only model on the English-only benchmarks.
We're excited to introduce MetaCLIP 2—the first practical recipe for training CLIP from scratch on worldwide web-scale data.
Our approach is surprisingly simple: through careful ablations, we identified the minimal set of changes needed to make English and non-English data work together.
The result? A recipe that creates mutual benefits between languages rather than forcing them to compete.
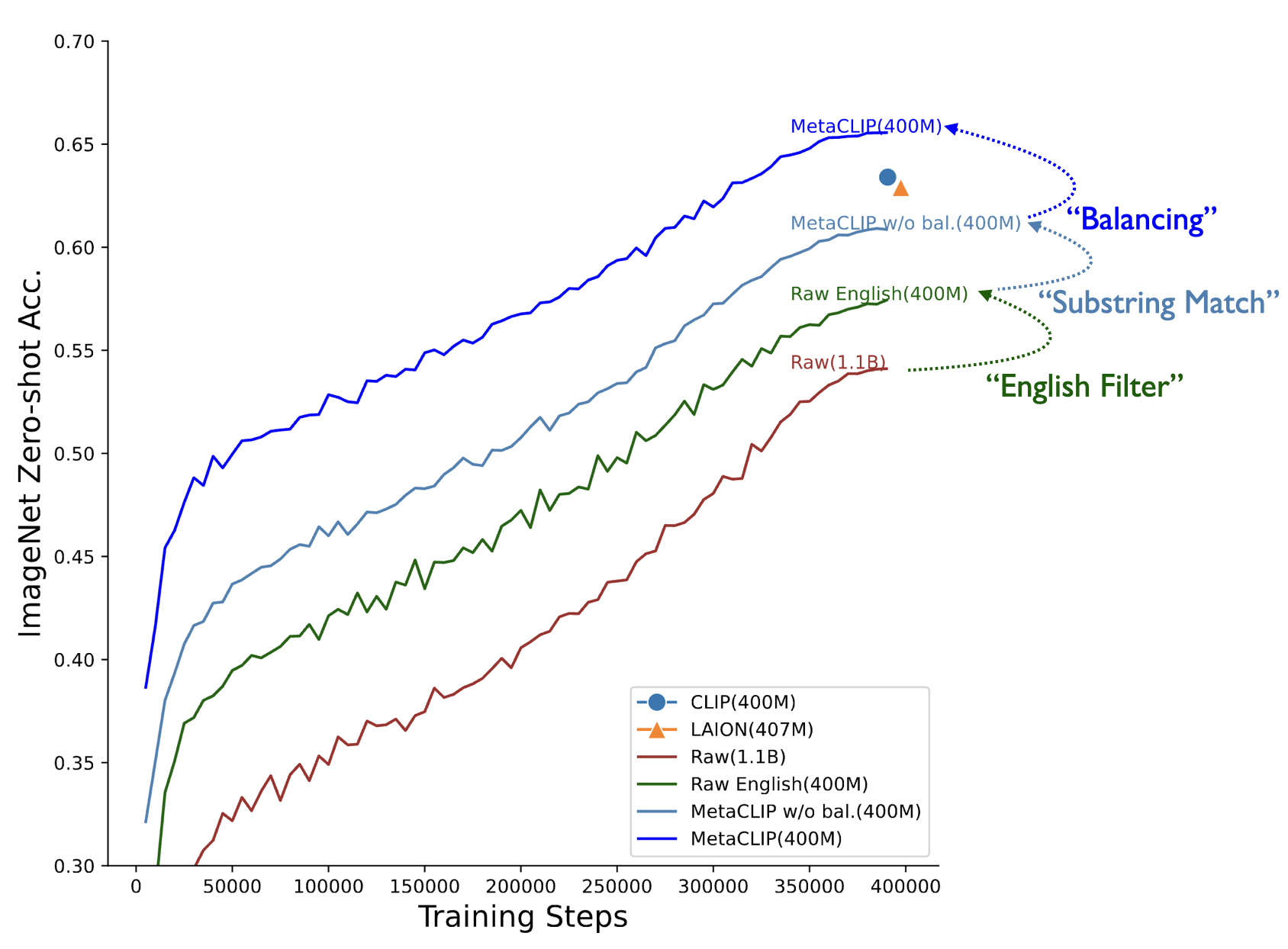
And it works. Our ViT-H/14 model beats its English-only counterpart by 0.8% on ImageNet zero-shot classification and outperforms mSigLIP by 0.7%.
More importantly, without any translation tricks or architectural gymnastics, we're setting new state-of-the-art results on multilingual benchmarks:
57.4% on CVQA, 50.2% on Babel-ImageNet, and 64.3% on XM3600 image-to-text retrieval.
The best part? English performance doesn't suffer—it actually improves.